Guruh sinovlari - Group testing
Yilda statistika va kombinatoriya matematikasi, guruh sinovlari - bu alohida ob'ektlarni emas, balki ob'ektlar guruhlari bo'yicha testlarga ma'lum ob'ektlarni aniqlash vazifasini buzadigan har qanday protsedura. Birinchi tomonidan o'rganilgan Robert Dorfman 1943 yilda guruh sinovlari - bu amaliy matematikaning nisbatan yangi sohasi bo'lib, u keng ko'lamli amaliy dasturlarda qo'llanilishi mumkin va bugungi kunda tadqiqotning faol yo'nalishi hisoblanadi.
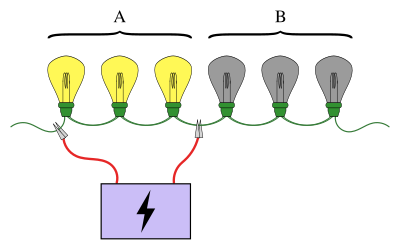
Guruh sinovlarining tanish namunasi ketma-ket ulangan lampochkalarni o'z ichiga oladi, bu erda lampochkalarning aniq bittasi singanligi ma'lum. Maqsad - eng kichik miqdordagi testlardan foydalangan holda singan lampochkani topish (bu erda lampochkalarning bir qismi elektr manbaiga ulanganida sinov bo'ladi). Oddiy yondashuv - har bir lampochkani alohida sinab ko'rish. Biroq, lampochkalarning soni ko'p bo'lsa, lampalarni guruhlarga birlashtirish ancha samarali bo'ladi. Masalan, lampochkalarning birinchi yarmini birdaniga ulab, singan lampochkaning qaysi yarmida ekanligini aniqlash mumkin, faqat bitta sinovda lampalarning yarmini chiqarib tashlaydi.
Guruh sinovlarini o'tkazish sxemalari oddiy yoki murakkab bo'lishi mumkin va har bir bosqichda ishtirok etadigan testlar har xil bo'lishi mumkin. Keyingi bosqich uchun testlar oldingi bosqichlar natijalariga bog'liq bo'lgan sxemalar deyiladi moslashuvchan protseduralar, barcha testlar oldindan ma'lum bo'lishi uchun ishlab chiqilgan sxemalar chaqiriladi moslashuvchan bo'lmagan protseduralar. Moslashuvchan bo'lmagan protsedurada ishtirok etadigan testlar sxemasining tuzilishi a deb nomlanadi hovuz dizayni.
Guruh sinovlari ko'plab dasturlarga ega, jumladan statistika, biologiya, informatika, tibbiyot, muhandislik va kiber xavfsizlik. Ushbu sinov sxemalariga zamonaviy qiziqish qayta tiklandi Inson genomining loyihasi.[1]
Asosiy tavsif va atamalar
Matematikaning ko'plab sohalaridan farqli o'laroq, guruh sinovlarining kelib chiqishi bitta hisobotdan kelib chiqishi mumkin[2] bitta odam tomonidan yozilgan: Robert Dorfman.[3] Motivatsiya Ikkinchi Jahon urushi paytida paydo bo'lgan Amerika Qo'shma Shtatlarining sog'liqni saqlash xizmati va Tanlangan xizmat barchani tozalash uchun keng ko'lamli loyihaga kirishdi sifilitik induksiyaga chaqirilgan erkaklar. Shaxsiy shaxsni sifilizga tekshirish, ulardan qon namunasini olishni, so'ngra sifiliz borligini yoki yo'qligini aniqlash uchun namunani tahlil qilishni o'z ichiga oladi. O'sha paytda ushbu testni o'tkazish qimmatga tushar edi va har bir askarni alohida sinovdan o'tkazish juda qimmat va samarasiz bo'lar edi.[3]
U erda bor deb taxmin qiling askarlar, bu sinov usuli olib keladi alohida testlar. Agar odamlarning katta qismi yuqtirilsa, bu usul oqilona bo'ladi. Ammo, erkaklarning juda ozgina qismi yuqtirilishi ehtimoli yuqori bo'lgan taqdirda, juda samarali sinov sxemasiga erishish mumkin. Sinovning samaraliroq sxemasini amalga oshirish maqsadga muvofiqligi quyidagi xususiyatlarga bog'liq: askarlarni guruhlarga birlashtirish va har bir guruhda qon namunalarini birlashtirish mumkin. Keyin birlashtirilgan namunani guruhdagi kamida bitta askarda sifiliz borligini tekshirish uchun tekshirish mumkin. Bu guruh sinovlarining asosiy g'oyasi. Agar ushbu guruhdagi bir yoki bir nechta askar sifiliz bilan kasallangan bo'lsa, unda test behuda o'tkaziladi (qaysi askar (lar) ekanligini topish uchun ko'proq testlarni o'tkazish kerak). Boshqa tomondan, agar hovuzda hech kimda sifilis yo'q bo'lsa, unda ko'plab testlar saqlanib qoladi, chunki bu guruhdagi har bir askar faqat bitta sinov bilan yo'q qilinishi mumkin.[3]

Guruhning ijobiy sinovini keltirib chiqaradigan narsalar odatda deyiladi nuqsonli narsalar (bular singan lampalar, sifilitik erkaklar va boshqalar). Ko'pincha buyumlarning umumiy soni quyidagicha belgilanadi va agar u tanilgan deb taxmin qilinsa, nuqsonlar sonini ifodalaydi.[3]

Guruh sinovlari muammolarini tasnifi
Guruh sinovlari uchun ikkita mustaqil tasnif mavjud; har bir guruh sinovi muammosi moslashuvchan yoki moslashuvchan bo'lmagan, yoki ehtimollik yoki kombinatoriyadir.[3]
Ehtimollik modellarida nuqsonli narsalar ba'zi birlariga amal qiladi deb taxmin qilinadi ehtimollik taqsimoti va maqsadi minimallashtirishdir kutilgan har bir buyumning nuqsonini aniqlash uchun zarur bo'lgan testlar soni. Boshqa tomondan, kombinatorial guruh sinovlari bilan, maqsad "eng yomon stsenariy" da zarur bo'lgan testlar sonini minimallashtirishdir, ya'ni minmax algoritmi - va nuqsonlarni taqsimlash to'g'risida hech qanday ma'lumot mavjud emas.[3]
Boshqa tasnif, moslashuvchanlik, qaysi elementlarni testga to'plashni tanlashda qanday ma'lumotlardan foydalanish mumkinligi bilan bog'liq. Umuman olganda, qaysi elementlarni sinab ko'rishni tanlash yuqoridagi lampochka muammosida bo'lgani kabi oldingi testlarning natijalariga bog'liq bo'lishi mumkin. An algoritm testni o'tkazib, so'ngra natijani (va o'tgan barcha natijalarni) ishlatib, navbatdagi qaysi testni amalga oshirishga qaror qiladi, bu adaptiv deb nomlanadi. Aksincha, moslashuvchan bo'lmagan algoritmlarda barcha testlar oldindan hal qilinadi. Ushbu g'oyani ko'p bosqichli algoritmlarga umumlashtirish mumkin, bu erda testlar bosqichlarga bo'linadi va keyingi bosqichda har bir test oldindan belgilab qo'yilishi kerak, faqat oldingi bosqichlarda test natijalari haqida ma'lumotga ega bo'lishiga qaramay adaptiv algoritmlar ko'proq erkinlikni taqdim etadi. dizayni, shuni ma'lumki, guruhni sinovdan o'tkazishning adaptiv algoritmlari moslashuvchan bo'lmaganlarga nisbatan nuqsonli elementlar to'plamini aniqlash uchun zarur bo'lgan testlar sonining doimiy omilidan ko'proq yaxshilanmaydi.[4][3] Bunga qo'shimcha ravishda, moslashuvchan bo'lmagan usullar amalda ko'pincha foydalidir, chunki test jarayonini samarali taqsimlashga imkon berib, avvalgi barcha test natijalarini tahlil qilmasdan ketma-ket testlarni davom ettirish mumkin.
O'zgarishlar va kengaytmalar
Guruh sinovlari muammosini kengaytirishning ko'plab usullari mavjud. Eng muhimlaridan biri deyiladi shovqinli guruh sinovlari va dastlabki muammoning katta farazlari bilan shug'ullanadi: bu sinovlar xatosiz. Guruh sinovi natijasi noto'g'ri bo'lishi ehtimoli mavjud bo'lganda (masalan, testda nuqsonlar bo'lmaganida ijobiy chiqadi) guruh sinovi muammosi shovqinli deb nomlanadi. The Bernulli shovqin modeli bu ehtimollik bir oz doimiy bo'lsa, , lekin umuman olganda, bu testdagi nuqsonlarning haqiqiy soniga va sinovdan o'tgan narsalar soniga bog'liq bo'lishi mumkin.[5] Masalan, suyultirish effekti testda mavjud bo'lgan nuqsonlar (yoki sinov qilingan sonning bir qismi sifatida ko'proq nuqsonlar) mavjud bo'lganda, ijobiy natija ehtimoli ko'proq bo'lishi bilan modellashtirilishi mumkin.[6] Shovqinli algoritm har doim nolga teng bo'lmagan xatoga yo'l qo'yadi (ya'ni elementni noto'g'ri belgilash).

Sinov natijalari ikkitadan ko'p bo'lishi mumkin bo'lgan stsenariylarni hisobga olgan holda guruh sinovlari kengaytirilishi mumkin. Masalan, test natijalariga ega bo'lishi mumkin va , nuqsonlar yo'qligi, bitta nuqson yoki noma'lum miqdordagi nuqsonlar mavjud. Umuman olganda, test natijalari to'plamini shunday deb hisoblash mumkin kimdir uchun .[3]




Yana bir kengaytma - bu to'plamlarni sinab ko'rish mumkin bo'lgan geometrik cheklovlarni ko'rib chiqish. Yuqoridagi lampochka muammosi bunday cheklovning namunasidir: faqat ketma-ket paydo bo'ladigan lampalarni sinab ko'rish mumkin. Xuddi shunday, buyumlar doira shaklida yoki umuman, to'rda joylashtirilishi mumkin, bu erda testlar grafadagi yo'llar mavjud. Geometrik cheklashning yana bir turi - bu guruhda sinovdan o'tkazilishi mumkin bo'lgan maksimal miqdordagi narsalar,[a] yoki guruh o'lchamlari teng bo'lishi kerak va hokazo. Xuddi shunday, har qanday element faqat ma'lum miqdordagi testlarda paydo bo'lishi mumkin bo'lgan cheklovni ko'rib chiqish foydali bo'lishi mumkin.[3]
Guruh sinovlarining asosiy formulasini remiks qilishni davom ettirishning cheksiz usullari mavjud. Quyidagi ishlab chiqishlar ba'zi ekzotik variantlar haqida ma'lumot beradi. "Yaxshi - o'rtacha - yomon" modelda har bir element "yaxshi", "o'rtacha" yoki "yomon" dan iborat bo'lib, test natijasi guruhdagi "eng yomon" narsaning turidir. Chegaraviy guruh sinovlarida guruhdagi nuqsonli narsalar soni biron bir chegara qiymatidan yoki mutanosiblikdan ko'p bo'lsa, test natijasi ijobiy bo'ladi.[7] Inhibitorlar bilan guruh sinovi - bu molekulyar biologiyada qo'llaniladigan variant. Bu erda ingibitorlar deb nomlangan moddalarning uchinchi klassi mavjud bo'lib, unda kamida bitta nuqson bo'lsa va inhibitorlar bo'lmasa, test natijasi ijobiy bo'ladi.[8]
Tarix va rivojlanish
Ixtiro va dastlabki taraqqiyot
Guruh sinovlari kontseptsiyasi birinchi bo'lib 1943 yilda Robert Dorfman tomonidan qisqa ma'ruzasida kiritilgan[2] ning Izohlar qismida nashr etilgan Matematik statistika yilnomalari.[3][b] Dorfmanning hisobotida - guruh sinovlari bo'yicha barcha dastlabki ishlarda bo'lgani kabi - ehtimollik muammosiga e'tibor qaratildi va guruhdagi testlarning yangi g'oyasidan foydalanib, ma'lum bir askarlar havzasidagi barcha sifilitli erkaklarni yo'q qilish uchun kutilgan test sonini kamaytirishga qaratilgan. Usul oddiy edi: askarlarni ma'lum hajmdagi guruhlarga ajratib oling va yuqtirganlarni aniqlash uchun musbat guruhlarda individual testlardan foydalaning (birinchi guruhdagi buyumlarni sinovdan o'tkazish). Dorfman ushbu strategiya bo'yicha guruhning eng maqbul o'lchamlarini populyatsiyada nuqsonlarning tarqalish darajasiga qarshi jadvalga kiritdi.[2]
1943 yildan so'ng, guruh sinovlari bir necha yil davomida deyarli ta'sirlanmadi. Keyin 1957 yilda Sterrett Dorfman protsedurasini takomillashtirdi.[10] Ushbu yangi jarayon yana ijobiy guruhlar bo'yicha individual testlarni o'tkazishdan boshlanadi, ammo nuqson aniqlangandan so'ng to'xtaydi. Keyin, guruhdagi qolgan narsalar birgalikda sinovdan o'tkaziladi, chunki ularning hech birida nuqson yo'q.
Guruh sinovlarining dastlabki to'liq muolajasi Sobel va Groll tomonidan ushbu mavzu bo'yicha 1959 yilda tuzilgan maqolalarida berilgan.[11] Ular beshta yangi protsedurani ta'rifladilar - keng tarqalganlikdan tashqari, tarqalish darajasi noma'lum bo'lganligi uchun va eng maqbul protsedura uchun ular foydalanadigan kutilayotgan testlar soni uchun aniq formulani taqdim etdilar. Qog'oz, shuningdek, guruh sinovlari bilan bog'liqlikni yaratdi axborot nazariyasi birinchi marta, shuningdek, guruh sinovlari muammosining bir nechta umumlashmalarini muhokama qilish va nazariyaning ba'zi yangi dasturlarini taqdim etish.
Kombinatorial guruh sinovlari
Guruh sinovlari birinchi marta 1962 yilda Li tomonidan kombinatorial kontekstda o'rganilgan,[12] ning kiritilishi bilan Li ning - bosqich algoritmi.[3] Li Dorfmanning "2 bosqichli algoritmini" o'zboshimchalik bilan ko'p sonli bosqichlarni kengaytirishni taklif qildi testlarni topishga kafolat berish yoki kamroq nuqsonlar ma'lumotlar.Fikr salbiy testlardagi barcha narsalarni olib tashlash va qolgan narsalarni dastlabki hovuzda bo'lgani kabi guruhlarga bo'lish edi. Bu amalga oshirilishi kerak edi individual testni o'tkazishdan oldin marta.



Keyinchalik Kombinatorial guruh sinovlari keyinchalik 1973 yilda Katona tomonidan to'liq o'rganildi.[13] Katona matritsaning namoyishi moslashuvchan bo'lmagan guruh sinovlari va moslashuvchan bo'lmagan 1-nuqsonli ishda nuqsonni topish tartibini ishlab chiqdi testlar, u ham optimal ekanligini isbotladi.

Umuman olganda, adaptiv kombinatorial guruh sinovlari uchun maqbul algoritmlarni topish qiyin va shunga qaramay hisoblash murakkabligi guruh sinovlari aniqlanmagan, shubhali qiyin ba'zi bir murakkablik sinfida.[3] Biroq, 1972 yilda muhim yutuq yuzaga keldi umumlashtirilgan ikkilik ajratish algoritmi.[14] Umumlashtirilgan ikkilik bo'linish algoritmi a bajarilishi bilan ishlaydi ikkilik qidirish ijobiy sinovdan o'tgan guruhlar bo'yicha va bu oddiy algoritm bo'lib, unda bitta nuqson topiladi axborot chegarasi testlar soni.
Ikki yoki undan ortiq nuqsonlar mavjud bo'lgan stsenariylarda, umumiy ikkilik bo'linish algoritmi hali ham eng maqbul natijalarni keltirib chiqaradi qaerda joylashgan pastki chegaradagi ma'lumotdan yuqori testlar bu nuqsonlar soni.[14] Bunga 2013 yilda Allemann tomonidan sezilarli yaxshilanishlar kiritilib, kerakli miqdordagi testlar o'tkazildi qachon pastki chegaradan yuqori ma'lumot va .[15] Bunga ikkilikni ajratish algoritmidagi ikkilik qidiruvni sinov guruhlari bir-biri bilan ustma-ust keladigan murakkab algoritmlar to'plamiga o'zgartirish orqali erishildi. Shunday qilib, ma'lum bir son yoki nuqsonlar sonining yuqori chegarasi bilan - adaptiv kombinatorial guruh sinovlari muammosi asosan hal qilindi, bu esa yanada takomillashtirishga imkon yaratmadi.




Shaxsiy test qachon o'tkazilishi to'g'risida ochiq savol mavjud minmax. Xu, Xvang va Vang 1981 yilda individual sinovlar qachon minmax ekanligini ko'rsatdilar va qachon minmax emasligini .[16] Hozirda bu chegaraning keskin ekanligi taxmin qilinmoqda: ya'ni individual test sinovlari minmax va agar shunday bo'lsa .[17][c] 2000 yilda Ricccio va Colbourn tomonidan biroz yutuqlarga erishildi, ular buni katta tomonga ko'rsatdilar , individual test qachon minmax bo'ladi .[18]




Moslashuvchan bo'lmagan va ehtimoliy sinovlar
Guruhlarni sinovdan o'tkazishda moslashuvchan bo'lmagan testlarni o'tkazishda muhim tushunchalardan biri shundaki, guruh sinovlari muvaffaqiyatli o'tishi ("kombinatoriya" muammosi) talabini bekor qilish, aksincha uning past, ammo past darajadagi bo'lishiga yo'l qo'yish orqali muhim yutuqlarga erishish mumkin. - har bir elementni noto'g'ri etiketlashning nolinchi ehtimoli ("ehtimollik" muammosi). Ma'lumki, nuqsonli narsalar soni buyumlarning umumiy soniga yaqinlashganda, aniq kombinatorial echimlar ehtimoliy echimlarga qaraganda ancha ko'proq sinovlarni talab qiladi - hattoki faqat bitta asimptotik kichik ehtimollik xato.[4][d]
Shu nuqtai nazardan, Chan va boshq. (2011) kiritilgan COMP, dan ko'p bo'lmagan narsani talab qiladigan ehtimollik algoritmi qadar topish uchun testlar nuqsonlar xato ehtimoli ko'proq bo'lgan narsalar .[5] Bu doimiy omil ichida pastki chegara.[4]



Chan va boshq. (2011) shuningdek, COMP-ni oddiy shovqinli modelga umumlashtirishni ta'minladi va shunga o'xshash ravishda aniq pastki chegaradan yuqorisida faqat doimiy (muvaffaqiyatsiz sinov ehtimoliga bog'liq) bo'lgan aniq ishlash ko'rsatkichlarini ishlab chiqardi.[4][5] Umuman olganda, Bernulli shovqin holatida talab qilinadigan testlar soni shovqinsiz holatga qaraganda doimiy doimiy omil.[5]
Aldrij, Baldassini va Jonson (2014) COMP algoritmining kengaytmasini ishlab chiqdilar, bu esa keyingi qayta ishlash bosqichlarini qo'shdi.[19] Ular ushbu yangi algoritmning ishlashi deb nomlanganligini ko'rsatdilar DD, COMP-dan qat'iy ravishda oshadi va DD bu erda "asosan maqbul" bo'ladi , uni oqilona tegmaslikni belgilaydigan taxminiy algoritm bilan taqqoslash orqali. Ushbu gipotetik algoritmning ishlashi shuni ko'rsatadiki, qachon yaxshilanish kerak , shuningdek, bu qanchalik yaxshilanishi mumkinligini ko'rsatmoqda.[19]


Kombinatorial guruh sinovlarini rasmiylashtirish
Ushbu bo'lim rasmiy ravishda guruh sinovlari bilan bog'liq tushunchalar va atamalarni belgilaydi.
- The kirish vektori, , uzunlikning ikkilik vektori ekanligi aniqlangan (anavi, ), bilan j- chaqirilayotgan element nuqsonli agar va faqat agar . Bundan tashqari, har qanday nuqsonli narsa "yaxshi" narsa deb nomlanadi.



nuqsonli narsalar (noma'lum) to'plamini tavsiflash uchun mo'ljallangan. Ning asosiy xususiyati bu yashirin kirish. Ya'ni, yozuvlar haqida to'g'ridan-to'g'ri ma'lumot yo'q ba'zi bir "sinovlar" orqali xulosa qilish mumkin bo'lgan narsalardan tashqari. Bu keyingi ta'rifga olib keladi.

- Ruxsat bering kirish vektori bo'ling. To'plam, deyiladi a sinov. Sinov qachon shovqinsiz, test natijasi ijobiy mavjud bo'lganda shu kabi va natija salbiy aks holda.


Shu sababli, guruh sinovlarining maqsadi "qisqa" seriyali testlarni tanlash usulini ishlab chiqishdir aniq yoki yuqori aniqlik bilan aniqlanishi kerak.
- Guruh-sinov algoritmi an deyiladi xato agar u buyumni noto'g'ri etiketlasa (ya'ni har qanday nuqsonli buyumni nuqsonli deb belgilasa yoki aksincha bo'lsa). Bu emas guruh sinovi natijasi noto'g'ri bo'lganligi bilan bir xil narsa. Algoritm deyiladi nol-xato agar uning xato qilish ehtimoli nolga teng bo'lsa.[e]
- har doim topish uchun zarur bo'lgan minimal test sonini bildiradi orasida nuqsonlar har qanday guruh sinov algoritmi bo'yicha xatolik ehtimoli nolga teng elementlar. Xuddi shu miqdor uchun, lekin algoritm moslashuvchan bo'lmagan cheklov bilan, yozuv ishlatilgan.


Umumiy chegaralar
Sozlash orqali individual testlarga murojaat qilish har doim ham mumkin bo'lganligi sababli har biriga , bu shunday bo'lishi kerak . Bundan tashqari, har qanday moslashuvchan bo'lmagan test protseduralari barcha testlarni natijalarini hisobga olmasdan oddiygina bajarish orqali adaptiv algoritm sifatida yozilishi mumkin, . Nihoyat, qachon , kamida bir narsa bor, uning nuqsoni aniqlanishi kerak (kamida bitta sinov orqali) va hokazo .






Xulosa qilib (taxmin qilganda) ), .[f]

Ma'lumot pastki chegara
Tushunchasi yordamida kerakli testlar sonining pastki chegarasini tavsiflash mumkin namuna maydoni, belgilangan , bu shunchaki nuqsonlarni mumkin bo'lgan joylashtirish to'plamidir. Namuna maydoni bilan har qanday guruh sinovi muammosi uchun va har qanday guruh-sinov algoritmi, buni ko'rsatish mumkin , qayerda xatolik ehtimoli nolga teng bo'lgan barcha nuqsonlarni aniqlash uchun zarur bo'lgan testlarning minimal soni. Bunga ma'lumot pastki chegara.[3] Ushbu chegara har bir testdan so'ng, har biri testning ikkita mumkin bo'lgan natijalaridan biriga mos keladigan ikkita ajratilgan kichik guruhlarga bo'linadi.



Biroq, quyi chegaradagi ma'lumotlarning o'zi, hatto kichik muammolar uchun ham amalga oshirilmaydi.[3] Buning sababi o'zboshimchalik bilan emas, chunki uni biron bir sinov yordamida amalga oshirish kerak.
Darhaqiqat, axborotning pastki chegarasi algoritm xato qilish ehtimoli nolga teng bo'lmagan hollarda umumlashtirilishi mumkin. Ushbu shaklda teorema testlar soniga qarab muvaffaqiyat ehtimoli bo'yicha yuqori chegarani beradi. Amalga oshiradigan har qanday guruh-sinov algoritmi uchun testlar, muvaffaqiyat ehtimoli, , qondiradi . Buni quyidagilarga kuchaytirish mumkin: .[5][20]



Moslashuvchan bo'lmagan algoritmlarni aks ettirish


Moslashuvchan bo'lmagan guruh sinovlari algoritmlari ikkita alohida fazadan iborat. Birinchidan, qancha test o'tkazilishi va har bir testga qaysi elementlarni kiritish kerakligi to'g'risida qaror qabul qilinadi. Tez-tez dekodlash bosqichi deb ataladigan ikkinchi bosqichda har bir guruh sinovlari natijalari tahlil qilinib, qaysi elementlarning nuqsoni bo'lishi mumkinligini aniqlaydi. Birinchi bosqich odatda matritsada quyidagicha kodlanadi.[5]
- Faraz qilaylik, adaptiv bo'lmagan guruh sinovi tartibi buyumlar testlardan iborat kimdir uchun . The sinov matritsasi chunki bu sxema ikkilik matritsa, , qayerda agar va faqat agar (va aks holda nolga teng).





Shunday qilib elementni ifodalaydi va har bir satr test bilan ifodalanadi ichida ekanligini ko'rsatuvchi yozuv testga kiritilgan element va a aksini ko'rsatib.





Vektor bilan bir qatorda (uzunlik ) noma'lum nuqsonli to'plamni tavsiflovchi, har bir test natijalarini tavsiflovchi natija vektorini kiritish odatiy holdir.
- Ruxsat bering moslashuvchan bo'lmagan algoritm tomonidan bajariladigan testlar soni. The natija vektori, , uzunlikning ikkilangan vektori (anavi, ) shu kabi agar faqat natijasi bo'lsa test ijobiy bo'ldi (ya'ni kamida bitta nuqson mavjud).[g]



Ushbu ta'riflar bilan moslashuvchan bo'lmagan muammoni quyidagicha qayta ko'rib chiqish mumkin: avval sinov matritsasi tanlanadi, , undan keyin vektor qaytariladi. Keyin muammo tahlil qilishda uchun ba'zi taxminlarni topish .

Doimiy ehtimollik mavjud bo'lgan eng oddiy shovqinli holatda , guruh sinovi noto'g'ri natijaga olib keladi, tasodifiy ikkilik vektorni ko'rib chiqadi, , bu erda har bir yozuv ehtimoli bor bo'lish va aks holda. Orqaga qaytarilgan vektor , odatdagi qo'shimcha bilan (teng ravishda bu element-dono XOR operatsiya). Shovqinli algoritm taxmin qilishi kerak foydalanish (ya'ni to'g'ridan-to'g'ri bilimsiz ).[5]




Moslashuvchan bo'lmagan algoritmlarning chegaralari
Matritsaning namoyishi moslashuvchan bo'lmagan guruh sinovlarida ba'zi chegaralarni isbotlashga imkon beradi. Yondashuv ko'plab deterministik dizaynlarni aks ettiradi, qaerda - quyida ta'riflanganidek, ajratiladigan matritsalar ko'rib chiqiladi.[3]
- Ikkilik matritsa, , deyiladi - ajraladigan agar har qanday mantiqiy yig'indisi (mantiqiy YOKI) uning ustunlari alohida. Bundan tashqari, yozuv - ajraladigan har qanday yig'indisi ekanligini bildiradi qadar ning ustunlari alohida. (Bu xuddi shunday emas bo'lish - har bir kishi uchun alohida .)



Qachon mavjudlik xususiyati bo'lgan sinov matritsasi - ajraladigan (- ajratib turadigan) bir-biridan ajrata olish qobiliyatiga tengdir nuqsonlar. Biroq, bu to'g'ridan-to'g'ri bo'lishiga kafolat bermaydi. Kuchli mulk, deyiladi - kelishmovchilik qiladi.
- Ikkilik matritsa, deyiladi - ajratish agar mantiqiy yig'indisi bo'lsa ustunlarda boshqa ustun mavjud emas. (Shu nuqtai nazardan, A ustunida B ustuni bor deyiladi, agar B har bir indeks uchun B 1 bo'lsa, A ham 1 ga ega.)
Ning foydali xususiyati - kelishilmagan test matritsalari - bu qadar nuqsonlar, har bir nuqson bo'lmagan narsa, natijasi salbiy bo'lgan kamida bitta testda paydo bo'ladi. Bu shuni anglatadiki, nuqsonlarni aniqlashning oddiy tartibi mavjud: faqat salbiy testda paydo bo'ladigan har qanday elementni olib tashlash kifoya.
Ning xususiyatlaridan foydalanish - ajraladigan va -dijunkt matritsalarni aniqlash uchun quyidagilarni ko'rsatish mumkin orasida nuqsonlar jami buyumlar.[4]
- Asimptotik jihatdan kichik bo'lgan testlar soni o'rtacha kabi xato o'lchovlari ehtimoli .
- Asimptotik jihatdan kichik bo'lgan testlar soni maksimal kabi xato o'lchovlari ehtimoli .
- A uchun zarur bo'lgan testlar soni nol kabi xato o'lchovlari ehtimoli .



Umumiy ikkilik ajratish algoritmi




Umumlashtirilgan ikkilik bo'linish algoritmi bu topadigan mohiyatan maqbul bo'lgan moslashuvchan guruh sinov algoritmi yoki kamroq nuqsonlar quyidagi narsalar:[3][14]
- Agar , sinovdan o'tkazing buyumlar alohida-alohida. Aks holda, o'rnating va .
- Bir o'lchamdagi guruhni sinab ko'ring . Agar natija salbiy bo'lsa, guruhdagi har bir narsa nuqsonli deb e'lon qilinadi; o'rnatilgan va 1-bosqichga o'ting. Aks holda, a dan foydalaning ikkilik qidirish chaqirilgan bitta nuqsonli va aniqlanmagan raqamni aniqlash uchun , qusur bo'lmagan narsalar; o'rnatilgan va . 1-bosqichga o'ting.








Umumiy ikkilik bo'linish algoritmi quyidagilarni talab qiladi sinovlar qaerda.[3]


Uchun katta, buni ko'rsatish mumkin ,[3] bilan solishtirganda Li uchun talab qilinadigan testlar - bosqich algoritmi. Aslida, umumlashtirilgan ikkilik ajratish algoritmi quyidagi ma'noda optimalga yaqin. Qachon buni ko'rsatish mumkin , qayerda bu pastki chegaradir.[3][14]






Moslashuvchan bo'lmagan algoritmlar
Guruhlarni sinovdan o'tkazishga moslashuvchan bo'lmagan algoritmlari nuqsonlar soni yoki hech bo'lmaganda ular bo'yicha yuqori chegara ma'lum deb taxmin qilishga moyil.[5] Ushbu miqdor belgilanadi ushbu bo'limda. Agar chegara ma'lum bo'lmasa, taxmin qilishda yordam beradigan so'rovlar murakkabligi past bo'lgan moslashuvchan bo'lmagan algoritmlar mavjud .[21]
Kombinatorial ortogonal moslashtirish (COMP)

Kombinatorial Ortogonal Matching Pursuit yoki COMP - bu oddiy moslashuvchan bo'lmagan guruh sinovlari algoritmi bo'lib, ushbu bo'limda keltirilgan yanada murakkab algoritmlarga asos bo'lib xizmat qiladi.
Birinchidan, test matritsasining har bir kiritilishi tanlanadi i.i.d. bolmoq ehtimollik bilan va aks holda.

Dekodlash bosqichi ustunlik bilan davom etadi (ya'ni element bo'yicha). Agar element paydo bo'lgan har bir test ijobiy bo'lsa, unda nuqson deb e'lon qilinadi; aks holda buyum nomukammal deb qabul qilinadi. Yoki ekvivalent ravishda, agar biror narsa natijasi salbiy bo'lgan har qanday testda paydo bo'lsa, mahsulot nuqsonli deb e'lon qilinadi; aks holda buyum nuqsonli deb hisoblanadi. Ushbu algoritmning muhim xususiyati shundaki, u hech qachon yaratmaydi yolg'on salbiy, garchi a noto'g'ri ijobiy bilan joylashgan barcha joylar j- ustun (nuqsonli narsaga mos keladi j) nuqsonli narsalarga mos keladigan boshqa ustunlar tomonidan "yashiringan".
COMP algoritmi ko'proq talab qilmaydi xatolik ehtimoli kam yoki teng bo'lgan sinovlar .[5] Bu yuqoridagi o'rtacha xato ehtimoli uchun pastki chegaraning doimiy koeffitsienti ichida.

Shovqinli vaziyatda, kimdir COMP algoritmidagi har qanday ustundagi joylashuvlar to'plami talabini yumshatadi. ijobiy elementga mos keladigan natijalar vektoridagi joylarning to'plamida to'liq mavjud. Buning o'rniga, ma'lum miqdordagi "mos kelmaslik" mumkin - bu nomuvofiqliklar soni har bir ustundagi sonlar soniga, shuningdek shovqin parametrlariga bog'liq, . Ushbu shovqinli COMP algoritmi ko'proq talab qilmaydi eng ko'p xato ehtimoliga erishish uchun testlar .[5]

Aniq nuqsonlar (DD)
Aniq nuqsonlar usuli (DD) har qanday noto'g'ri pozitsiyani olib tashlashga harakat qiladigan COMP algoritmining kengaytmasi. DD uchun ishlash kafolatlari COMP-dan qat'iyan oshib ketganligi ko'rsatilgan.[19]
Dekodlash bosqichida COMP algoritmining foydali xususiyati ishlatiladi: COMP nomukammal deb e'lon qilgan har bir element, albatta, nuqsonli emas (ya'ni noto'g'ri negativlar mavjud emas). U quyidagicha davom etadi.
- Avvalo COMP algoritmi ishga tushiriladi va u aniqlagan har qanday nuqson yo'q qilinadi. Qolgan barcha narsalar endi "ehtimol nuqsonli".
- Keyinchalik algoritm barcha ijobiy testlarni ko'rib chiqadi. Agar biror narsa testda yagona "mumkin bo'lgan nuqson" sifatida paydo bo'lsa, unda u nuqsonli bo'lishi kerak, shuning uchun algoritm uni nuqsonli deb e'lon qiladi.
- Boshqa barcha narsalar nuqsonli emas deb taxmin qilinadi. Ushbu so'nggi qadamning asoslanishi nuqsonlar soni buyumlarning umumiy sonidan ancha kam degan taxmindan kelib chiqadi.
E'tibor bering, 1 va 2-bosqichlar hech qachon xato qilmaydi, shuning uchun algoritm faqat nuqsonli elementni nuqsonli deb e'lon qilganda xato qilishi mumkin. Shunday qilib DD algoritmi faqat noto'g'ri negativlarni yaratishi mumkin.
Ketma-ket COMP (SCOMP)
SCOMP (ketma-ket COMP) - bu DD so'nggi bosqichga qadar hech qanday xato qilmasligidan foydalanadigan algoritm, bu erda qolgan narsalar nuqsonli emas deb taxmin qilinadi. E'lon qilingan nuqsonlar to'plami bo'lsin . Ijobiy test chaqiriladi tushuntirdi tomonidan agar unda kamida bitta element bo'lsa . SCOMP-ning asosiy kuzatuvi shundaki, DD tomonidan topilgan nuqsonlar to'plami har bir ijobiy testni tushuntirmasligi mumkin va har bir tushuntirilmagan testda yashirin nuqson bo'lishi kerak.

Algoritm quyidagicha davom etadi.
- Olish uchun DD algoritmining 1 va 2 bosqichlarini bajaring , nuqsonlar to'plami uchun dastlabki taxmin.
- Agar har bir ijobiy testni tushuntiradi, algoritmni bekor qiladi: nuqsonlar to'plamining yakuniy bahosi.
- Agar tushuntirib berilmagan testlar bo'lsa, eng ko'p tushuntirilmagan testlarda paydo bo'ladigan "mumkin bo'lgan nuqson" ni toping va uni nuqsonli deb e'lon qiling (ya'ni uni to'plamga qo'shing) ). 2-bosqichga o'ting.
Simulyatsiyalarda SCOMP eng maqbul darajada ishlashini ko'rsatdi.[19]
Namunaviy dasturlar
Guruh sinovlari nazariyasining umumiyligi uni ko'plab turli xil dasturlarga, shu jumladan klon skrining, elektr kalta shimlarni topishga imkon beradi;[3] yuqori tezlikdagi kompyuter tarmoqlari;[22] tibbiy ko'rik, miqdordagi qidiruv, statistika;[16] mashinada o'rganish, DNKning ketma-ketligi;[23] kriptografiya;[24][25] ma'lumotlar ekspertizasi.[26] Ushbu bo'lim ushbu dasturlarning kichik tanlovi haqida qisqacha ma'lumot beradi.
Multiaccess kanallari

A ko'p kanalli kanal bir vaqtning o'zida ko'plab foydalanuvchilarni bog'laydigan aloqa kanali. Har bir foydalanuvchi kanalda tinglashi va uzatishi mumkin, lekin agar bir vaqtning o'zida bir nechta foydalanuvchi uzatsa, signallar to'qnashadi va tushunarsiz shovqinga aylanadi. Multiaccess kanallari turli xil real dasturlar, xususan simsiz kompyuter tarmoqlari va telefon tarmoqlari uchun muhimdir.[27]
Ko'p kirish kanallari bilan bog'liq muhim muammo shundaki, foydalanuvchilarga ularning xabarlari to'qnashmasligi uchun uzatish vaqtlarini qanday belgilash kerak. Oddiy usul - har bir foydalanuvchiga o'z vaqtini uzatish uchun zarur bo'lgan vaqt oralig'ini berish uyalar. (Bu deyiladi vaqtni multiplekslash, yoki TDM.) Biroq, bu juda samarasiz, chunki u foydalanuvchilarga xabar bo'lmasligi mumkin bo'lgan uzatish uyalarini tayinlaydi va odatda istalgan vaqtda faqat bir nechta foydalanuvchi uzatishni xohlaydi, aks holda ko'p kanalli kanal birinchi navbatda amaliy emas.
Guruh sinovlari sharoitida ushbu muammo odatda "davrlar" ga bo'linish yo'li bilan quyidagi tarzda hal qilinadi.[3] Agar epoxaning boshida xabar bo'lsa, foydalanuvchi "faol" deb nomlanadi. (If a message is generated during an epoch, the user only becomes active at the start of the next one.) An epoch ends when every active user has successfully transmitted their message. The problem is then to find all the active users in a given epoch, and schedule a time for them to transmit (if they have not already done so successfully). Here, a test on a set of users corresponds to those users attempting a transmission. The results of the test are the number of users that attempted to transmit, va , corresponding respectively to no active users, exactly one active user (message successful) or more than one active user (message collision). Therefore, using an adaptive group testing algorithm with outcomes , it can be determined which users wish to transmit in the epoch. Then, any user that has not yet made a successful transmission can now be assigned a slot to transmit, without wastefully assigning times to inactive users.


Machine learning and compressed sensing
Mashinada o'qitish is a field of computer science that has many software applications such as DNA classification, fraud detection and targeted advertising. One of the main subfields of machine learning is the 'learning by examples' problem, where the task is to approximate some unknown function when given its value at a number of specific points.[3] As outlined in this section, this function learning problem can be tackled with a group-testing approach.
In a simple version of the problem, there is some unknown function, qayerda va (using logical arithmetic: addition is logical OR and multiplication is logical AND). Bu yerda shunday sparse', which means that at most of its entries are . The aim is to construct an approximation to foydalanish point evaluations, where imkon qadar kichikroq.[4] (Exactly recovering corresponds to zero-error algorithms, whereas is approximated by algorithms that have a non-zero probability of error.)






In this problem, recovering is equivalent to finding . Bundan tashqari, if and only if there is some index, , qayerda . Thus this problem is analogous to a group-testing problem with defectives and total items. Yozuvlari are the items, which are defective if they are , specifies a test, and a test is positive if and only if .[4]



In reality, one will often be interested in functions that are more complicated, such as , again where . Siqilgan sezgi, which is closely related to group testing, can be used to solve this problem.[4]

In compressed sensing, the goal is to reconstruct a signal, , by taking a number of measurements. These measurements are modelled as taking the dot product of with a chosen vector.[h] The aim is to use a small number of measurements, though this is typically not possible unless something is assumed about the signal. One such assumption (which is common[30][31]) is that only a small number of entries of bor muhim, meaning that they have a large magnitude. Since the measurements are dot products of , tenglama ushlab turadi, qaerda a matrix that describes the set of measurements that have been chosen and is the set of measurement results. This construction shows that compressed sensing is a kind of 'continuous' group testing.





The primary difficulty in compressed sensing is identifying which entries are significant.[30] Once that is done, there are a variety of methods to estimate the actual values of the entries.[32] This task of identification can be approached with a simple application of group testing. Here a group test produces a complex number: the sum of the entries that are tested. The outcome of a test is called positive if it produces a complex number with a large magnitude, which, given the assumption that the significant entries are sparse, indicates that at least one significant entry is contained in the test.
There are explicit deterministic constructions for this type of combinatorial search algorithm, requiring o'lchovlar.[33] However, as with group-testing, these are sub-optimal, and random constructions (such as COMP) can often recover sub-linearly in .[32]


Multiplex assay design for COVID19 testing
During a pandemic such as the COVID-19 outbreak in 2020, virus detection assays are sometimes run using nonadaptive group testing designs.[34][35] One example was provided by the Origami Assays project which released open source group testing designs to run on a laboratory standard 96 well plate.[36]

In a laboratory setting, one challenge of group testing is the construction of the mixtures can be time-consuming and difficult to do accurately by hand. Origami assays provided a workaround for this construction problem by providing paper templates to guide the technician on how to allocate patient samples across the test wells.[37]
Using the largest group testing designs (XL3) it was possible to test 1120 patient samples in 94 assay wells. If the true positive rate was low enough, then no additional testing was required.
Shuningdek qarang: List of countries implementing pool testing strategy against COVID-19.
Data forensics
Data forensics is a field dedicated to finding methods for compiling digital evidence of a crime. Such crimes typically involve an adversary modifying the data, documents or databases of a victim, with examples including the altering of tax records, a virus hiding its presence, or an identity thief modifying personal data.[26]
A common tool in data forensics is the one-way cryptographic hash. This is a function that takes the data, and through a difficult-to-reverse procedure, produces a unique number called a hash.[men] Hashes, which are often much shorter than the data, allow us to check if the data has been changed without having to wastefully store complete copies of the information: the hash for the current data can be compared with a past hash to determine if any changes have occurred. An unfortunate property of this method is that, although it is easy to tell if the data has been modified, there is no way of determining how: that is, it is impossible to recover which part of the data has changed.[26]
One way to get around this limitation is to store more hashes – now of subsets of the data structure – to narrow down where the attack has occurred. However, to find the exact location of the attack with a naive approach, a hash would need to be stored for every datum in the structure, which would defeat the point of the hashes in the first place. (One may as well store a regular copy of the data.) Group testing can be used to dramatically reduce the number of hashes that need to be stored. A test becomes a comparison between the stored and current hashes, which is positive when there is a mismatch. This indicates that at least one edited datum (which is taken as defectiveness in this model) is contained in the group that generated the current hash.[26]
In fact, the amount of hashes needed is so low that they, along with the testing matrix they refer to, can even be stored within the organisational structure of the data itself. This means that as far as memory is concerned the test can be performed 'for free'. (This is true with the exception of a master-key/password that is used to secretly determine the hashing function.)[26]
Izohlar
- ^ The original problem that Dorfman studied was of this nature (although he did not account for this), since in practice, only a certain number of blood sera could be pooled before the testing procedure became unreliable. This was the main reason that Dorfman’s procedure was not applied at the time.[3]
- ^ However, as is often the case in mathematics, group testing has been subsequently re-invented multiple times since then, often in the context of applications. For example, Hayes independently came up with the idea to query groups of users in the context of multiaccess communication protocols in 1978.[9]
- ^ This is sometimes referred to as the Hu-Hwang-Wang conjecture.
- ^ The number of tests, , must scale as for deterministic designs, compared to for designs that allow arbitrarily small probabilities of error (as va ).[4]
- ^ One must be careful to distinguish between when a test reports a false result and when the group-testing procedure fails as a whole. It is both possible to make an error with no incorrect tests and to not make an error with some incorrect tests. Most modern combinatorial algorithms have some non-zero probability of error (even with no erroneous tests), since this significantly decreases the number of tests needed.
- ^ In fact it is possible to do much better. For example, Li's -stage algorithm gives an explicit construction were .
- ^ Shu bilan bir qatorda can be defined by the equation , where multiplication is mantiqiy VA () and addition is mantiqiy YOKI (). Bu yerda, bo'ladi holatida agar va faqat agar va ikkalasi ham har qanday kishi uchun . That is, if and only if at least one defective item was included in the sinov.
- ^ This kind of measurement comes up in many applications. For example, certain kinds of digital camera[28] or MRI machines,[29] where time constraints require that only a small number of measurements are taken.
- ^ More formally hashes have a property called collision resistance, which is that the likelihood of the same hash resulting from different inputs is very low for data of an appropriate size. In practice, the chance that two different inputs might produce the same hash is often ignored.











Adabiyotlar
Iqtiboslar
- ^ Kolborn, Charlz J.; Dinits, Jeffri H. (2007), Kombinatoriya dizaynlari bo'yicha qo'llanma (2-nashr), Boka Raton: Chapman & Hall / CRC, p. 574, Section 46: Pooling Designs, ISBN 978-1-58488-506-1
- ^ a b v Dorfman, Robert (December 1943), "The Detection of Defective Members of Large Populations", Matematik statistika yilnomalari, 14 (4): 436–440, doi:10.1214/aoms/1177731363, JSTOR 2235930
- ^ a b v d e f g h men j k l m n o p q r s t siz v w Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapur: Jahon ilmiy. ISBN 978-9810212933.
- ^ a b v d e f g h men Atia, George Kamal; Saligrama, Venkatesh (March 2012). "Boolean compressed sensing and noisy group testing". Axborot nazariyasi bo'yicha IEEE operatsiyalari. 58 (3): 1880–1901. arXiv:0907.1061. doi:10.1109/TIT.2011.2178156.
- ^ a b v d e f g h men j Chun Lam Chan; Pak Hou Che; Jaggi, Sidharth; Saligrama, Venkatesh (1 September 2011), "2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton)", 49th Annual Allerton Conference on Communication, Control, and Computing, pp. 1832–1839, arXiv:1107.4540, doi:10.1109/Allerton.2011.6120391, ISBN 978-1-4577-1817-5
- ^ Hung, M.; Swallow, William H. (March 1999). "Robustness of Group Testing in the Estimation of Proportions". Biometriya. 55 (1): 231–237. doi:10.1111/j.0006-341X.1999.00231.x. PMID 11318160.
- ^ Chen, Hong-Bin; Fu, Hung-Lin (April 2009). "Nonadaptive algorithms for threshold group testing". Diskret amaliy matematika. 157 (7): 1581–1585. doi:10.1016/j.dam.2008.06.003.
- ^ De Bonis, Annalisa (20 July 2007). "New combinatorial structures with applications to efficient group testing with inhibitors". Kombinatorial optimallashtirish jurnali. 15 (1): 77–94. doi:10.1007/s10878-007-9085-1.
- ^ Hayes, J. (August 1978). "An adaptive technique for local distribution". Aloqa bo'yicha IEEE operatsiyalari. 26 (8): 1178–1186. doi:10.1109/TCOM.1978.1094204.
- ^ Sterrett, Andrew (December 1957). "On the detection of defective members of large populations". Matematik statistika yilnomalari. 28 (4): 1033–1036. doi:10.1214/aoms/1177706807.
- ^ Sobel, Milton; Groll, Phyllis A. (September 1959). "Group testing to eliminate efficiently all defectives in a binomial sample". Bell tizimi texnik jurnali. 38 (5): 1179–1252. doi:10.1002/j.1538-7305.1959.tb03914.x.
- ^ Li, Chou Hsiung (June 1962). "A sequential method for screening experimental variables". Amerika Statistik Uyushmasi jurnali. 57 (298): 455–477. doi:10.1080/01621459.1962.10480672.
- ^ Katona, Gyula O.H. (1973). "A survey of combinatorial theory". Combinatorial Search Problems. North-Holland, Amsterdam: 285–308.
- ^ a b v d Hwang, Frank K. (September 1972). "A method for detecting all defective members in a population by group testing". Amerika Statistik Uyushmasi jurnali. 67 (339): 605–608. doi:10.2307/2284447. JSTOR 2284447.
- ^ Allemann, Andreas (2013). "An efficient algorithm for combinatorial group testing". Information Theory, Combinatorics, and Search Theory: 569–596.
- ^ a b Hu, M. C.; Xvan, F. K .; Wang, Ju Kwei (June 1981). "A Boundary Problem for Group Testing". SIAM algebraik va diskret usullar jurnali. 2 (2): 81–87. doi:10.1137/0602011.
- ^ Leu, Ming-Guang (28 October 2008). "A note on the Hu–Hwang–Wang conjecture for group testing". ANZIAM jurnali. 49 (4): 561. doi:10.1017/S1446181108000175.
- ^ Riccio, Laura; Colbourn, Charles J. (1 January 2000). "Sharper bounds in adaptive group testing". Tayvan matematikasi jurnali. 4 (4): 669–673. doi:10.11650/twjm/1500407300.
- ^ a b v d Aldridge, Matthew; Baldassini, Leonardo; Johnson, Oliver (June 2014). "Group Testing Algorithms: Bounds and Simulations". Axborot nazariyasi bo'yicha IEEE operatsiyalari. 60 (6): 3671–3687. arXiv:1306.6438. doi:10.1109/TIT.2014.2314472.
- ^ Baldassini, L.; Jonson, O .; Aldridge, M. (1 July 2013), "2013 IEEE International Symposium on Information Theory", IEEE Axborot nazariyasi bo'yicha xalqaro simpozium, pp. 2676–2680, arXiv:1301.7023, CiteSeerX 10.1.1.768.8924, doi:10.1109/ISIT.2013.6620712, ISBN 978-1-4799-0446-4
- ^ Sobel, Milton; Elashoff, R. M. (1975). "Group testing with a new goal, estimation". Biometrika. 62 (1): 181–193. doi:10.1093/biomet/62.1.181. hdl:11299/199154.
- ^ Bar-Noy, A .; Xvan, F. K .; Kessler, I.; Kutten, S. (1 May 1992). A new competitive algorithm for group testing. Eleventh Annual Joint Conference of the IEEE Computer and Communications Societies. 2. pp. 786–793. doi:10.1109/INFCOM.1992.263516. ISBN 978-0-7803-0602-8.
- ^ Damaschke, Peter (2000). "Adaptive versus nonadaptive attribute-efficient learning". Mashinada o'rganish. 41 (2): 197–215. doi:10.1023/A:1007616604496.
- ^ Stinson, D. R.; van Trung, Tran; Wei, R (May 2000). "Secure frameproof codes, key distribution patterns, group testing algorithms and related structures". Statistik rejalashtirish va xulosalar jurnali. 86 (2): 595–617. CiteSeerX 10.1.1.54.6212. doi:10.1016/S0378-3758(99)00131-7.
- ^ Colbourn, C. J.; Dinitz, J. H.; Stinson, D. R. (1999). "Communications, Cryptography, and Networking". Kombinatorika bo'yicha tadqiqotlar. 3 (267): 37–41. doi:10.1007/BF01609873.
- ^ a b v d e Gudrix, Maykl T.; Atalloh, Mixail J.; Tamassia, Roberto (7 June 2005). Indexing information for data forensics. Amaliy kriptografiya va tarmoq xavfsizligi. Kompyuter fanidan ma'ruza matnlari. 3531. 206-221 betlar. CiteSeerX 10.1.1.158.6036. doi:10.1007/11496137_15. ISBN 978-3-540-26223-7.
- ^ Chlebus, B. S. (2001). "Randomized communication in radio networks". In: Pardalos, P. M.; Rajasekaran, S.; Reif, J.; Rolim, J. D. P. (Eds.), Tasodifiy hisoblash bo'yicha qo'llanma, Jild I, p.401–456. Kluwer Academic Publishers, Dordrecht.
- ^ Takhar, D.; Laska, J. N.; Wakin, M. B.; Duarte, M. F.; Baron, D .; Sarvotham, S.; Kelly, K. F.; Baraniuk, R. G. (February 2006). "A new compressive imaging camera architecture using optical-domain compression". Elektron tasvirlash. Computational Imaging IV. 6065: 606509–606509–10. Bibcode:2006SPIE.6065...43T. CiteSeerX 10.1.1.114.7872. doi:10.1117/12.659602.
- ^ Candès, E. J. (2014). "Mathematics of sparsity (and a few other things)". Xalqaro matematiklar Kongressi materiallari. Seul, Janubiy Koreya.
- ^ a b Gilbert, A. C.; Iwen, M. A.; Strauss, M. J. (October 2008). "Group testing and sparse signal recovery". 42nd Asilomar Conference on Signals, Systems and Computers: 1059–1063. Elektr va elektronika muhandislari instituti.
- ^ Rayt, S. J .; Nowak, R. D.; Figueiredo, M. A. T. (July 2009). "Sparse Reconstruction by Separable Approximation". Signalni qayta ishlash bo'yicha IEEE operatsiyalari. 57 (7): 2479–2493. Bibcode:2009ITSP...57.2479W. CiteSeerX 10.1.1.142.749. doi:10.1109/TSP.2009.2016892.
- ^ a b Berinde, R.; Gilbert, A. C.; Indyk, P.; Karloff, H.; Strauss, M. J. (September 2008). Combining geometry and combinatorics: A unified approach to sparse signal recovery. 46th Annual Allerton Conference on Communication, Control, and Computing. pp. 798–805. arXiv:0804.4666. doi:10.1109/ALLERTON.2008.4797639. ISBN 978-1-4244-2925-7.
- ^ Indyk, Piotr (1 January 2008). "Explicit Constructions for Compressed Sensing of Sparse Signals". O'n to'qqizinchi yillik diskret algoritmlar bo'yicha ACM-SIAM simpoziumi materiallari: 30–33.
- ^ Ostin, Devid. "AMS Feature Column — Pooling strategies for COVID-19 testing". Amerika matematik jamiyati. Olingan 2020-10-03.
- ^ Prasanna, Dheeraj. "Tapestry pooling". tapestry-pooling.herokuapp.com. Olingan 2020-10-03.
- ^ "Origami Assays". Origami Assays. 2020 yil 2-aprel. Olingan 7 aprel, 2020.
- ^ "Origami Assays". Origami Assays. 2020 yil 2-aprel. Olingan 7 aprel, 2020.
Umumiy ma'lumotnomalar
- Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapur: Jahon ilmiy. ISBN 978-9810212933.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2007), Lectures 7.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2010), Lectures 10, 11, 28, 29
- Du, D., & Hwang, F. (2006). Pooling Designs and Nonadaptive Group Testing. Boston: Twayne Publishers.
- Aldridge, M., Johnson, O. and Scarlett, J. (2019), Group Testing: An Information Theory Perspective, Foundations and Trends® in Communications and Information Theory: Vol. 15: No. 3-4, pp 196-392. doi:10.1561/0100000099
- Ely Porat, Amir Rothschild: Explicit Non-adaptive Combinatorial Group Testing Schemes. ICALP (1) 2008: 748–759
- Kagan, Eugene; Ben-gal, Irad (2014), "A group testing algorithm with online informational learning", IIE operatsiyalari, 46 (2): 164–184, doi:10.1080/0740817X.2013.803639, ISSN 0740-817X